猜你喜欢其实就是推荐系统的一种,人们在日常的购物网站中,推荐系统跟人人是息息相关的。
为什么需要推荐系统?
随着互联网行业的井喷式发展,获取信息的方式越来越多,人们从主动获取信息逐渐变成了被动接受信息,信息量也在以几何倍数式爆发增长。举一个例子,PC时代用google reader,常常有上千条未读博客更新;如今的微信公众号,也有大量的红点未阅读。垃圾信息越来越多,导致用户获取有价值信息的成本大大增加。为了解决这个问题,我个人就采取了比较极端的做法:直接忽略所有推送消息的入口。但在很多时候,有效信息的获取速度极其重要。

由于信息的爆炸式增长,对信息获取的有效性,针对性的需求也就自然出现了。推荐系统应运而生。
最早的推荐系统应该是亚马逊为了提升长尾货物的用户抵达率而发明的。已经有数据证明,长尾商品的销售额以及利润总和与热门商品是基本持平的。亚马逊网站上在线销售的商品何止百万,但首页能够展示的商品数量又极其有限,给用户推荐他们可能喜欢的商品就成了一件非常重要的事情。当然,商品搜索也是一块大蛋糕,亚马逊的商品搜索早已经开始侵蚀谷歌的核心业务了。
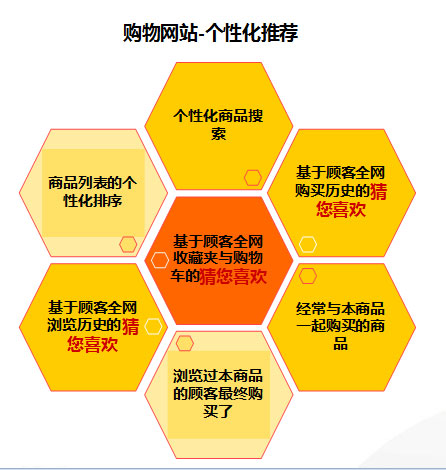
基于内容的推荐:
tag 给商品打上各种tag:运动商品类,快速消费品类,等等。粒度划分越细,推荐结果就越精确
商品名称,描述的关键字 通过从商品的文本描述信息中提取关键字,从而利用关键字的相似来作推荐
同商家的不同商品 用户购买了商店的一件商品,就推荐这个商店的其他热销商品
利用经验,人为地做一些关联 一个经典的例子就是商店在啤酒架旁边摆上纸尿布。那么,在网上购买啤酒的人,也可以推荐纸尿布?
数据清理
当我们开始有意识地记录用户行为数据后,得到的用户数据会逐渐地爆发式增长。就像录音时存在的噪音一样,获取的用户数据同样存在着大量的垃圾信息。因此,拿到数据的第一步,就是对数据做清理。其中最核心的工作,就是减噪和归一化:
减噪:用户行为数据是在用户的使用过程中产生的,其中包含了大量的噪音和用户误操作。比如因为网络中断,用户在短时间内产生了大量点击的操作。通过一些策略以及数据挖掘算法,来去除数据中的噪音。
归一化:清理数据的目的是为了通过对不同行为进行加权,形成合理的用户偏好矩阵。用户会产生多种行为,不同行为的取值范围差距可能会非常大。比如:点击次数可能远远大于购买次数,直接套用加权算法,可能会使得点击次数对结果的影响程度过大。于是就需要归一算法来保证不同行为的取值范围大概一致。最简单的归一算法就是将各类数据来除以此类数据中的最大值,以此来保证所有数据的取值范围都在[0,1]区间内。
推荐系统具有高度复杂性,需要持续地进行改进。可能在同一时间内,需要上线不同的推荐算法,做A/B test。根据用户对推荐结果的行为数据,不断对算法进行优化,改进。要走的路还很长:路漫漫其修远兮,吾将上下而求索。
|



